Automatic classification of texts from the Touristic courpus – TURK. 10 million running words, ~5000 documents.
Properties and most important findings:
- 26 different categories, very unbalanced data,
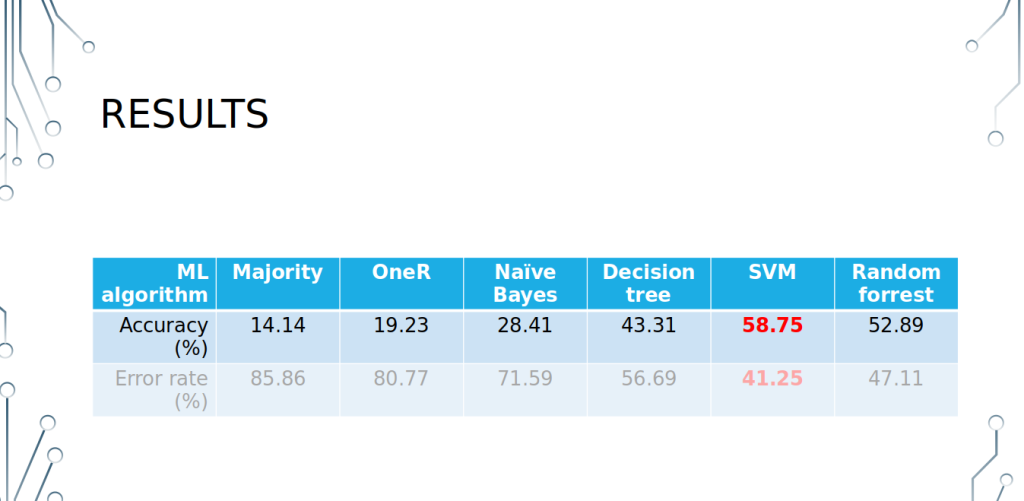
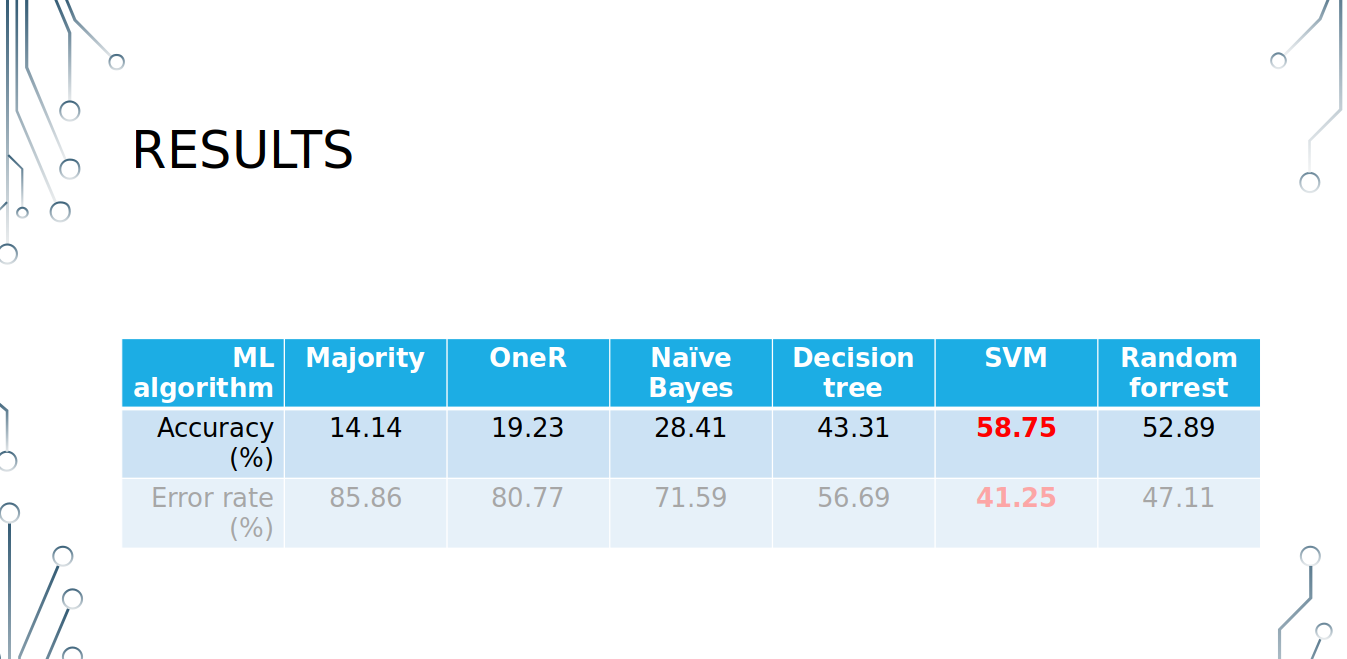
- Majority category = just around 14% of data,
- No single feature by itself can accurately predict the category (~19% acc),
- Features are highly dependent (NB acc = ~28%),
- SVM does the best job (~59% acc),
- Biggest error on rare categories,
- Smalles error on frequent categories (accuracy up to more than 90%).